After implementing a set of new activation functions in DeepTrainer (see my previous post) I had to come to the conclusion that most modern activation functions require different treatment than the almighty Hyperbolic Tangent. With TanH I could conveniently use the same activation function for all layers and neurons in the network, and it worked like charm for all training algorithms. However, activation functions like ReLU require at least a different activation for the output layer, otherwise the training will be very likely to go wrong.
So I decided to implement separately selectable activation functions for every layer in the network. This implementation is already checked in to the repository on Git.
From the API’s point of view this means that you will have to provide a list of activation functions when initializing the network, similarly to the list of neuron count in each layer:
[sourcecode language=”csharp”]
var parameters = new NeuralNetworkParameters(
filename, // Path to CSV file containing Input & Target data
new List<uint> { 1, 32, 64, 32, 5 }, // Neuron count in each layer. First is number of inputs, last is number of outputs
new List<ActivationType> { // List of activation functions in each layer.
ActivationType.Linear, // First represents the input layer. No activation needed here. Always Linear.
ActivationType.PReLU, // Activation functions of hidden layers
ActivationType.PReLU, // Activation functions of hidden layers
ActivationType.PReLU, // Activation functions of hidden layers
ActivationType.HyperbolicTangent}); // Activation function of the output layer
network = new NeuralNetwork(parameters); // Initializing the network with parameters
[/sourcecode]
At the moment the implementation utilizes polymorphism through an interface and virtual functions which is translated to vtable lookups by the compiler. This is not an ideal solution performance-wise, so I am still working on a way to cache these activation functions which could improve the performance.
The UI for the WPF application has changed a bit, now it allows you to select the activation from combo boxes for each layer:
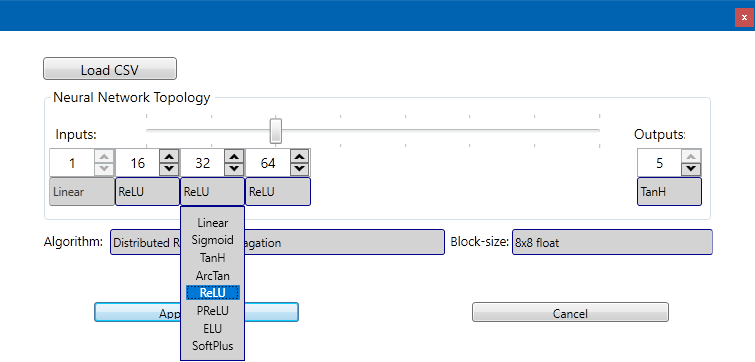
At this moment using PReLU activation for the hidden layers with a Hyperbolic Tangent output layer activation seems to work very well, both with backpropagation and resilient propagation, the convergence of the network seems much faster than before.
Here is a video of training a network with 1 input, 5 outputs, and three hidden layers with 16, 32 and 64 neurons. The hidden layers use PReLU, and the output layer uses TanH activation.
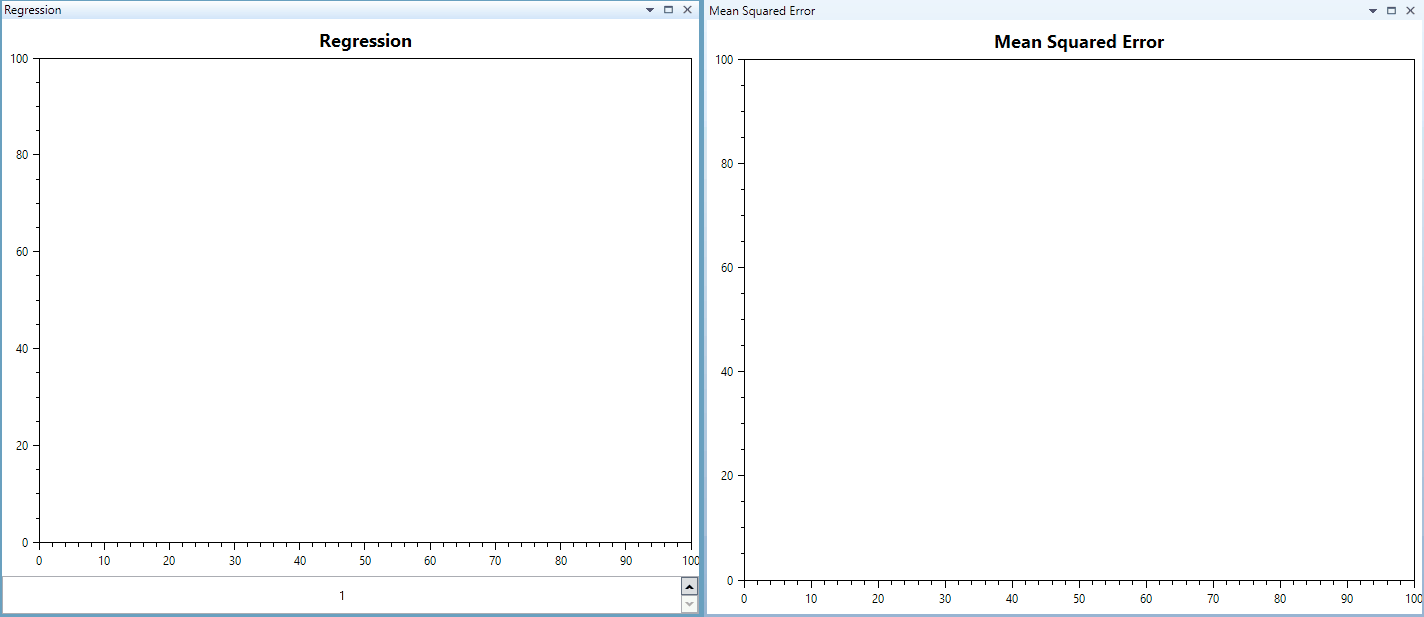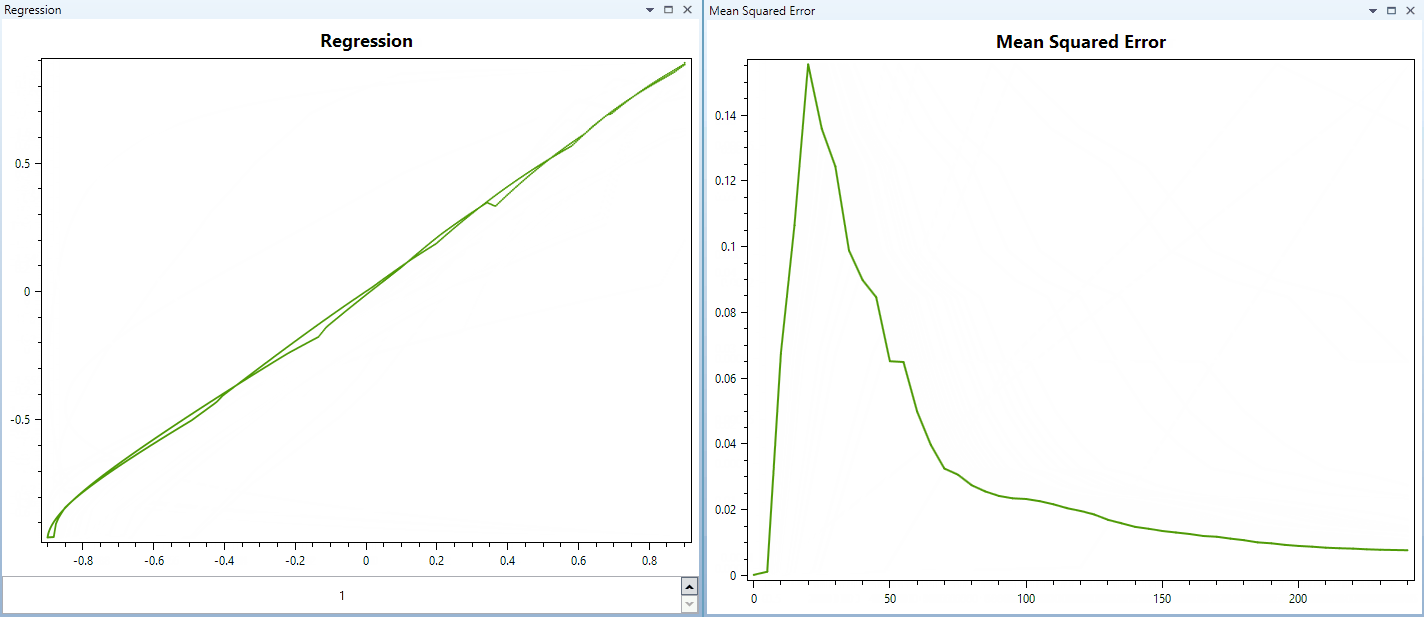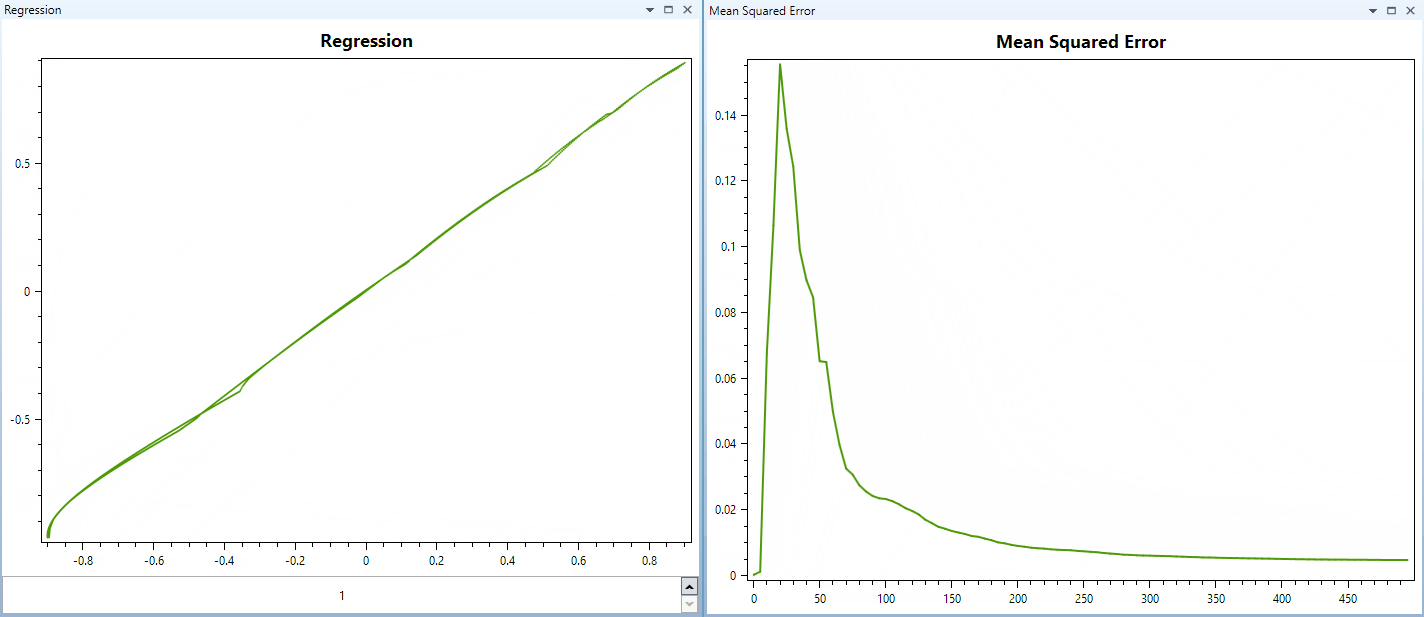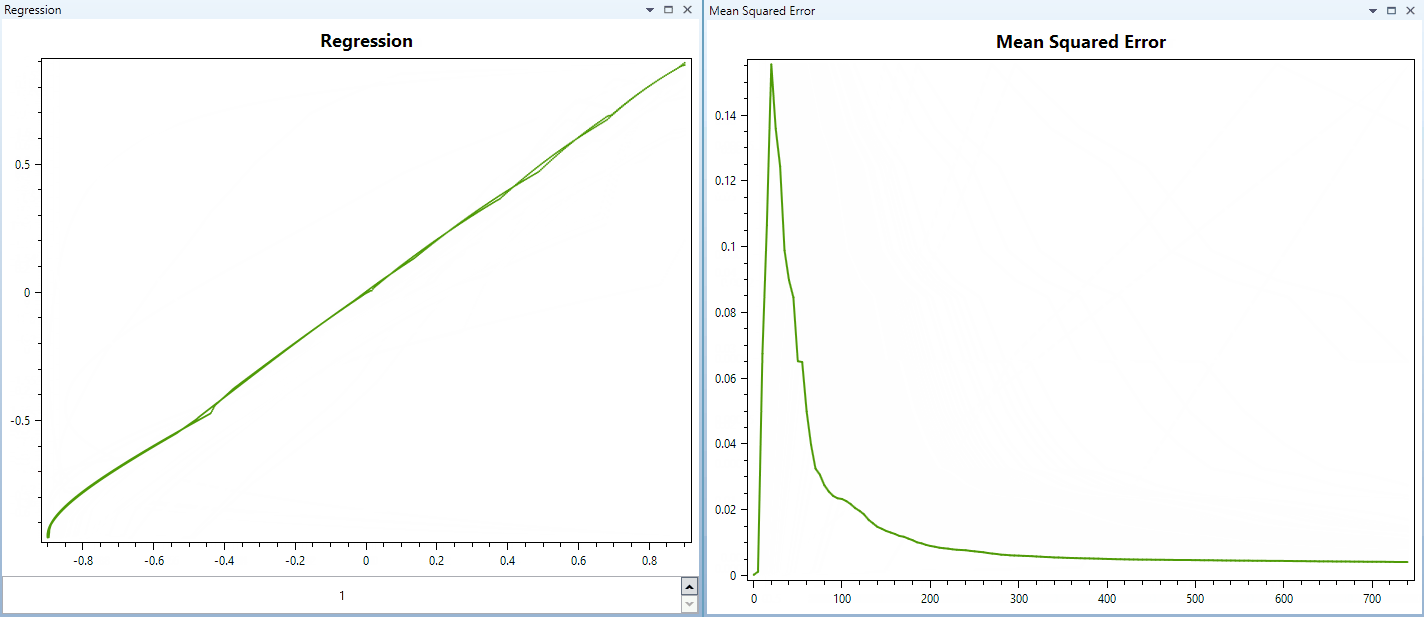
And this video below shows training a network with similar parameters, but using Hyperbolic Tangent as activation for all hidden layers and the output layer too. The training pattern is the same. (The regression of the first output/target relationship displayed in these videos are samples from a parabola function.)
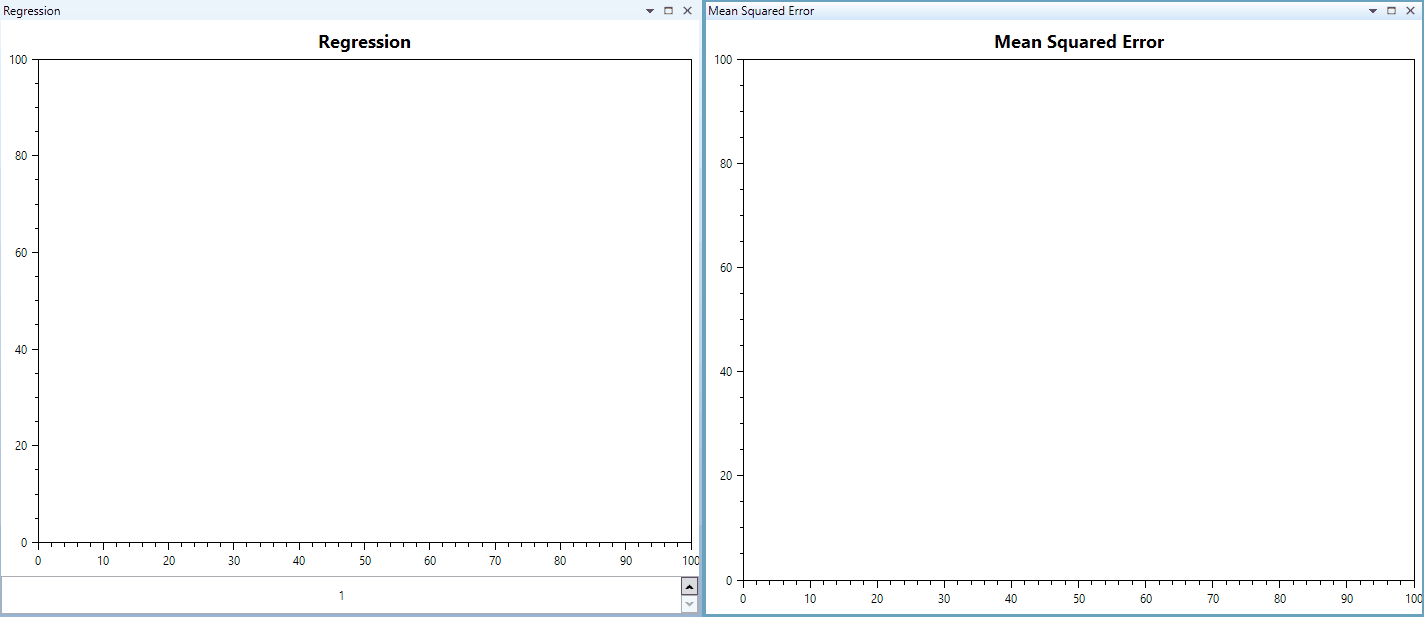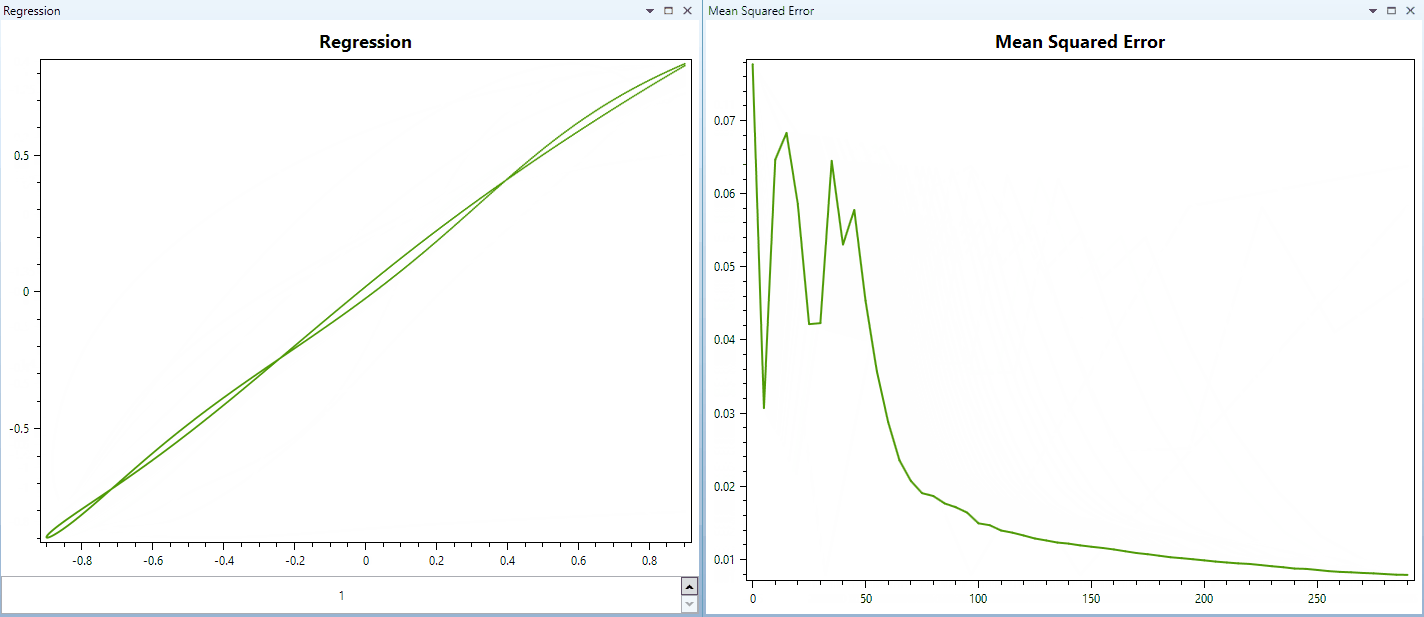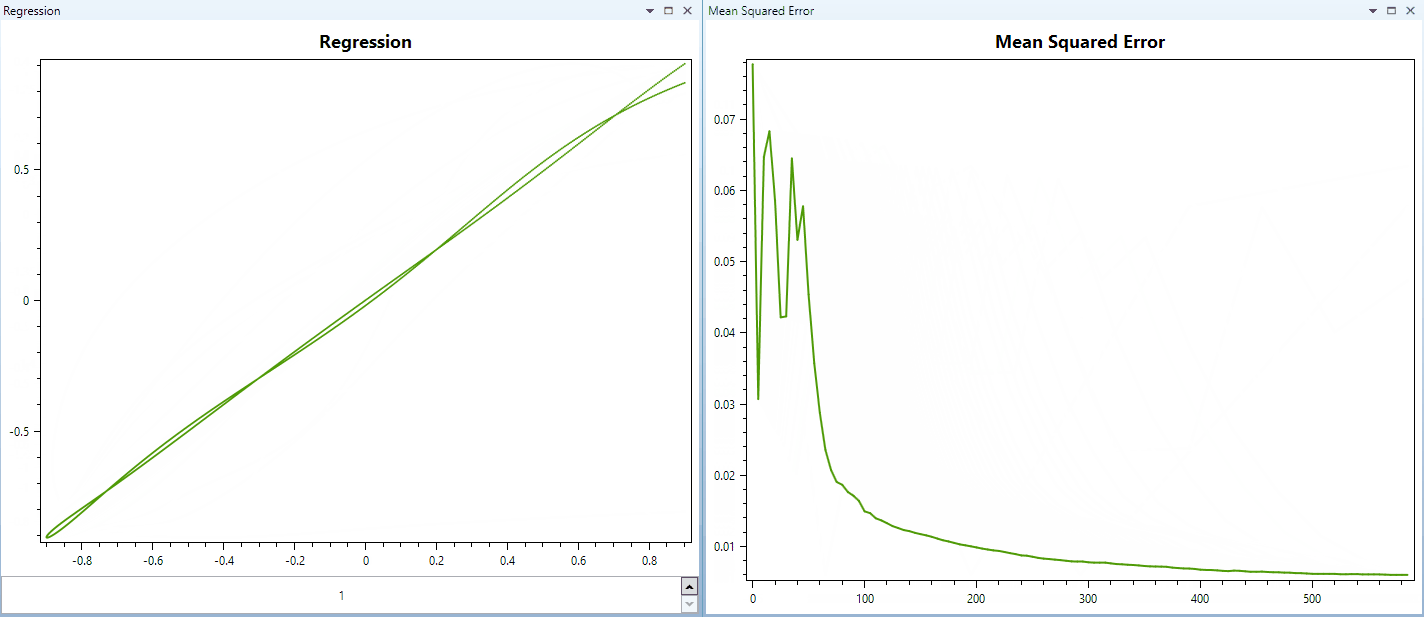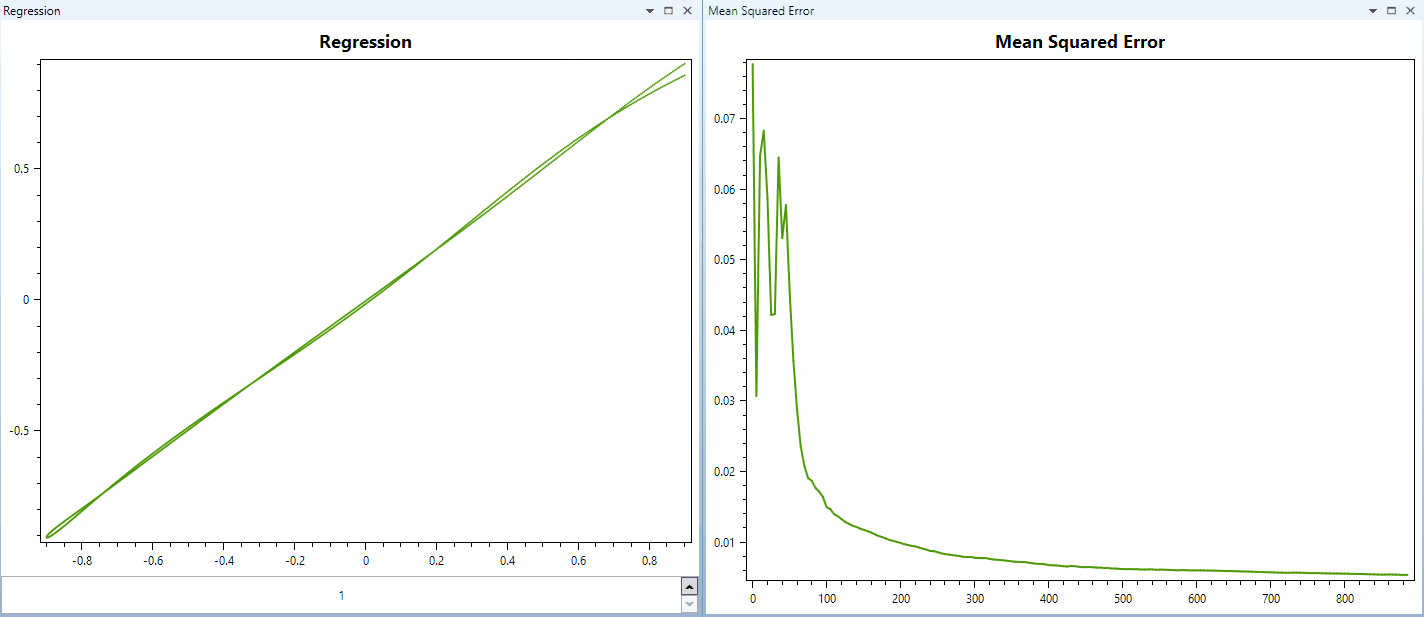
As soon as I have further updates or performance measurements I am going to update this post.