What is new in DeepTrainer
Over the weekend I updated the codebase with 6 new activation functions. My original aim was to try out the ReLU function as I heard that many modern applications these days are using it, so it came to me as an obvious challenge I needed to accept. Besides ReLU I added 5 more activation functions too, for certain problems one may be superior to the others, it is very hard to select a clear winner for all possible problems.
At this point I am over with a lot of experimentation with networks that are only using one activation function for all layers. The ReLU activation function however demands different treatment. Although I was able to train networks fully using ReLU through all the layers, I would say it only works more or less properly in 10% of the cases – probably depending on the random initialization of the weights and the biases. My next obvious step will have to be introducing per-layer granularity for the activation function as well, which would allow you to change the activation type for each layer separately. (Coming soon.)
Revisiting Activation Functions
Up until now the DeepTrainer library was only using the Hyperbolic Tangent activation function, mainly because of legacy reasons. Originally back in the early 2000’s I tried only Sigmoid and TanH, and TanH came out for me as a winner because it stretches through the [-1, +1] interval – however in actual implementation this feature is not making it superior in performance.
Performance-wise neither the Sigmoid, nor the TanH functions are the best possible choices. For forward propagation Sigmoid requires a floating point exponential calculation, and TanH is a trigonometric function (also expressible with exponential functions). Both are very expensive. For backward propagation their derivatives become fairly simple to calculate because you can reuse the output values of neurons – basically you don’t have to recalculate the expensive exponential or trigonometric functions.
What is an Activation Function after all?
However, as use of Neural Networks started gaining momentum again in this decade more new Activation Functions were discovered by mathematicians that are able to provide the exact same performance but with much less computation.
Activation functions – without weighing involved – are nothing more than simple switches that act as filters for incoming values. If the input signal is too small, they close, but if the input signal reaches a certain level, they let it through. Weights are responsible for adjusting the level at which this filter should open/close. Another good way of thinking about them – now in terms of a network – is as if they were a hierarchical tree of if-else conditions. Of course if you tried creating a neural network with if-else you would run into the problem of continuity. These functions (or switches) must show continuity so that they could be differentiated for the training algorithm.
The nice S shaped curvature of the Sigmoid and the TanH activation functions are not providing much extra value for the neural network – as it turns out after applying other, new types of activation functions.
The ArcTan activation function
On the graph below I am comparing the hyperbolic tangent and the arcus tangent activation functions and their derivatives. As you can see, the hyperbolic tangent is a convergent function, but the arcus tangent is divergent. However, the most important difference for implementation’s point of view is in their derivatives. While it was easy to express the derivative of the tanh function utilizing the original function, you can’t do this with arctan.
For backwards propagation this means that the previously calculated output of the neuron can’t be utilized for calculating the derivative, instead you will have to use the input value of the neuron again for the derivative too!
(On the above graph I was making use of a C constant parameter too to adjust the steepness of the activation function and its derivative.)
Comparing other activation functions
Below is a table of possible activation functions that work well with neural networks. I have found this nice summary of these functions on the web, so I hope they don’t mind if I reuse it here:
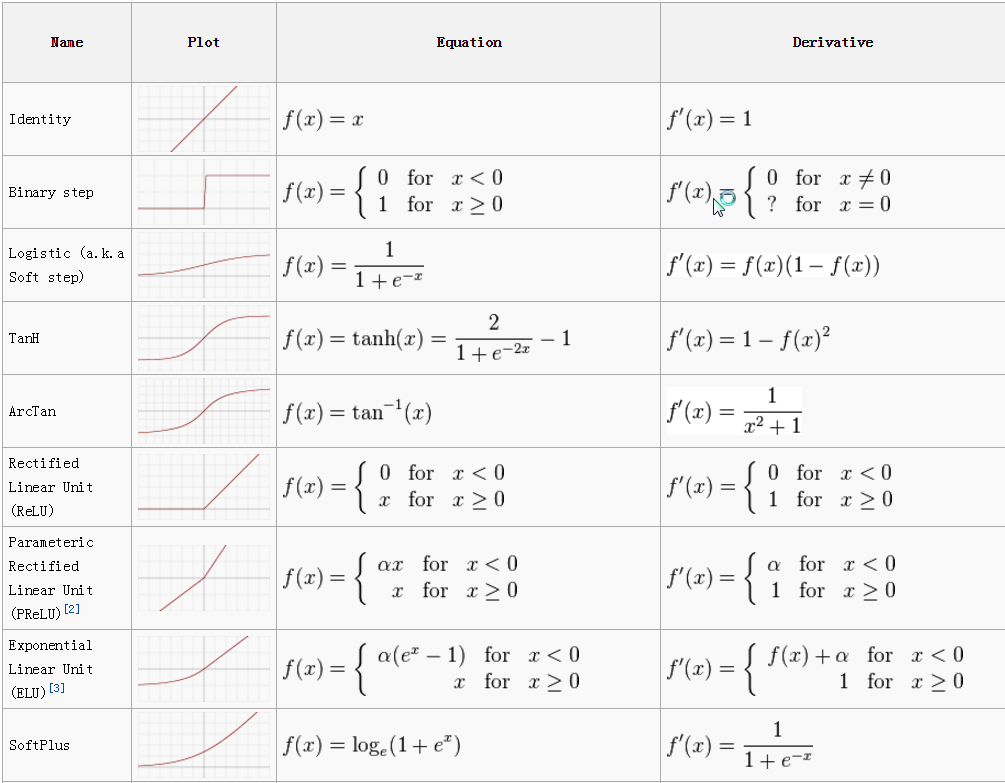
Please note:
- Sigmoid (also called Logistic or Soft Step) and TanH are capable of utilizing the already calculated output of the neuron. This is why you see f(x) in their derivative, instead of x.
- ELU needs both the input of the neuron (x), and also its output ( f(x) ).
- On the other hand ArcTan, ReLU, PReLU and SoftPlus are only making use of the input value (x) of the neuron.
The winner is… ReLU
Performance-wise it is easy to spot the clear winner out of these functions. Obviously identity and binary step functions are out of question for neural networks, so we have to look at only the rest.
Of course it is the ReLU function, because it does not even require a floating point calculation of any sort! All it needs is an if-else condition.
All the above functions are now implemented in DeepTrainer. Wherever I could I also included a Steepness multiplier in the code, except for the ReLU function, because it would ruin its performance advantage by introducing a floating point instruction.
ReLU activation is very sensitive to weight initialisation and to the normalization range of the input data (and this is probably true for all newly introduced activation functions). At this point I am still working on trying to find a best method that would always lead to successful learning. If you are looking for a robust algorithm I would suggest you to keep using RProp with TanH activation, or BackProp with Sigmoid.
N.B.: In the above table the value of α can be safely set to 0.01. Also, if you use the code and you are certain that you will always use the same activation function (e.g. ReLU), I would suggest getting rid of the dependency-injected IActivation polymorphic classes and their virtual functions, and inline the forward and backward activations of your choice directly. For performance-critical applications vtable lookups inside loops are costly and not recommended.
Graphs of activation functions
Below I created graphs for each activation function and their derivatives separately.
Sigmoid:
Hyperbolic Tangent:
Arcus Tangent:
ReLU:
PReLU:
ELU:
SoftPlus: