Ok, my apologies in advance if you expected artificial intelligence agents playing with each other in this post, I couldn’t help myself when I wrote the title. This post is about comparing the speeds of two significantly different implementations of the same neural network algorithm.

I’ve just done a very simple performance comparison between my neural network algorithm implementations (no exact time measurements though). Both applications are using a 1x10x10x10x5 Neural Network model, and both are learning the same amount of sample data.
- In the left corner:
- Old C++ code from the uni 15 years ago,
- Written in Borland C++ Builder 6,
- Fixed size containers for network parameters
- Implemented with arrays and lots of raw pointers,
- For loops with if/else conditions for matrix algorithms
- Mental amount of copy constructor calls when returning temporary matrices by value,
- Simple but should be fast.
- In the right corner:
- C++11 implementation
- Dynamic container sizes
- With lots of smart pointers
- Lots of vtable access,
- Move constructor semantics,
- Uses STL algorithms for almost everything except matrix product
- Transpose_iterator implementation that fakes a transposed matrix without actually shuffling the data – transposing a matrix is now flipping a boolean
- Wrapped in CLI/C++
- Displayed in C# WinForms.
Both are release builds started within 20 iterations from each other.
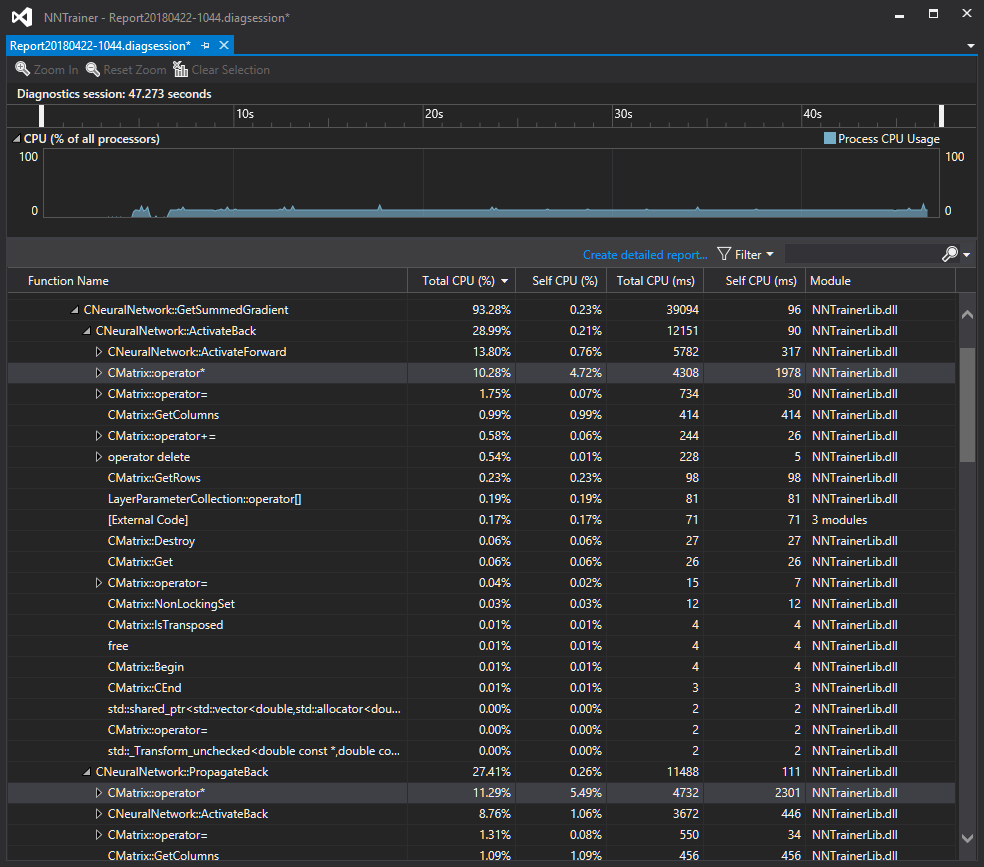
The new implementation is the clear winner, but it is very surprising by how little – by only 11.8%. Clearly there is a lot to improve in the performance. I think it’s time to start doing some serious profiling to find the worst offenders.
(Update: the worst offender is the already expected one, the matrix multiplication operator takes around 18% of the whole CPU time.)
Both implementations can be downloaded with source code from GitHub:
My plans for further performance improvement include using SSE intrinsics and after that a CUDA core implementation. Tensor Core CUDA 9 implementation will have to wait though until I can afford to put my hands on a Volta card. (I need a “donate” button.)
Update 2: I have optimised the loops in the matrix multiplication algorithm:
- pre-fetching const values before the loops
- pre-fetching a function pointer to the right Getter function (transposed vs normal), saving an extra if/else condition from inside the loop
the speed difference between the two applications jumped to 35.8% – which is a lot more pleasing for me to see. The speed gain also shows in the profiler, the CPU spends around 16% less time in the matrix multiplier operator compared to the previous build.