Positive results
My marketing department that’s just around in the bedroom (where dreams come t̶r̶u̶e̶ and go) have been bugging me to continue the AI Fight sequel so here it is. When I reach #XVI someone please warn me diplomatically to stop otherwise it will gain consciousness and start its own Netflix pilot.
There is not really THAT much I could be happy about in terms of performance, but still I managed to achieve some great results:
- First of all implementing layer-granularity for activation functions brings in some performance gain, because on the hidden layers I can use ReLU or PReLU activation which are computationally much less expensive compared to the hyperbolic tangent function and its derivative.
- I have found a more optimal and robust network topology that actually emphasizes the gain from activation functions. My network I am using for measurement has now 1 input, 128 – 256 – 128 neurons in its three hidden layers all using PReLU activation, and 5 output layers using hyperbolic tangent. This means 66304 neural connections (or weights) in the network.
- I have changed how the performance is measured, leaving a much longer period for calculating the average speed, and as a result now I don’t have to wait for a long time until it slowly converges to a maximum value, I am able to see the result already after a few iterations.
- I finally started using my PC as it was advertised originally when I bought it, and overclocked the Core i7 CPU from 4.0 to 4.6 GHz. (Strong and stable as Brexit.)
Before I jump to overclocking (which is almost like cheating) first I made some measurements with only using hyperbolic tangent activation on all layers. The results were surprisingly good, probably because of the new network topology I was using. The speed measured 403 MCpS (Mega-Connections per Second, or million neural connections processed per second), which is almost a 100 MCpS faster than my last measurements. (The fastest speed I measured on this PC before was 313 MCpS.) This is utilizing 8 hardware threads, single precision floating point arithmetics with 8×8 block matrix partitions on a 4.0 GHz Core i7 computer. This is 12615 KCpS/GHz/Core which I find quite impressive compared to the previous 9937 KCps/GHz/Core measurement.
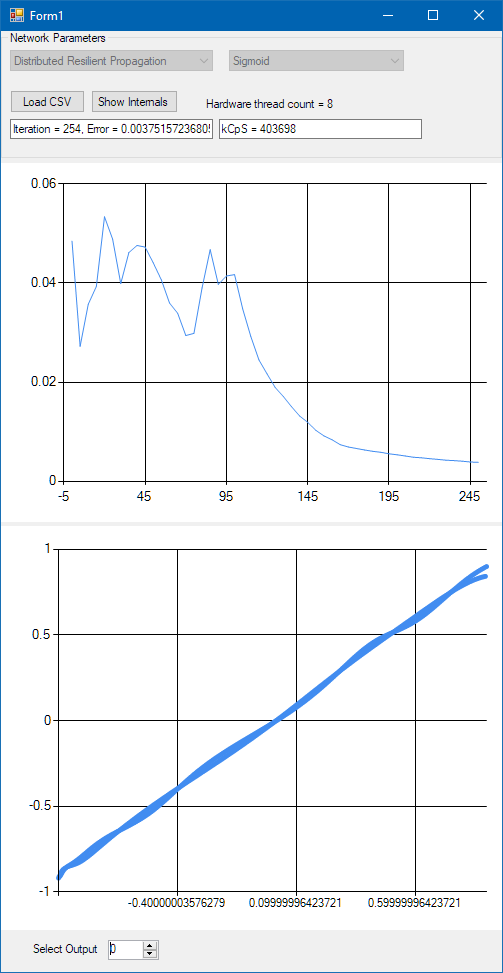
After this I changed the activation functions to PReLU and I also overclocked the CPU to 4.6 GHz. (And at this point I also turned down the heating in my living room as the CPU was making noticeable difference in the room temperature, and our winters are also quite mild these days. Artificial Intelligence against climate change? Well, probably not, just kidding.)
So the result was 522 MCpS, which is 14180 KCpS/GHz/Core. I think I have reached the limit of the capabilities of this CPU, while this last measurement was anything but useful. First of all the convergence of the network slowed down significantly because of the unnecessarily high number of neurons on each layer. As you may see on the screenshot below I didn’t have the patience to wait until the error converges to a global minimum, but convergence does not affect the performance measurement in any way.
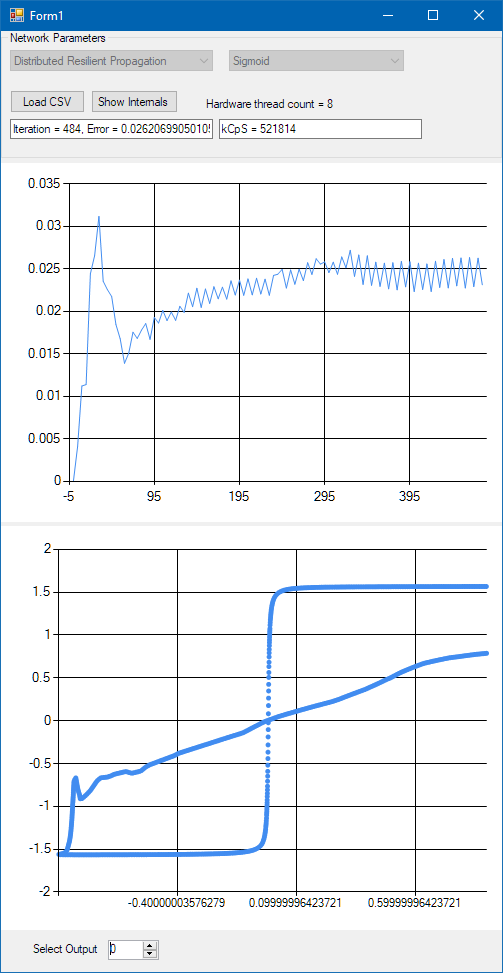
Negative results
Recently I also started working on a GPU based algorithm, and started learning CUDA C/C++. First I implemented a matrix multiplier algorithm that creates 16×16 block partitions from the matrices and multiplies them in parallel. The results were shocking at first, and not at all in a good way. The overall performance dropped to 600 KCpS – not a typo, indeed Kilo-Connections per Second, which is 3-4 magnitudes slower than the CPU was. Of course there is a good reason for all this, and this was my fault. For each and every matrix I first allocated device memory using cudaMalloc, then copied the matrix to the device by using cudaMemcpy, and after the kernel finished with the calculations I copied the result back to host memory with another cudaMemcpy (and called cudaFree). Well, this actually meant the following:
- The arrays containing the matrices reached the DMA controller of my PC, and from there they went to the PCI Express bus.
- They took off the bus at a nearby pub and walked in.
- There they ordered some beers and some steak.
- When they finished they took the bus again and headed back to the apartment.
- Here they reached the memory controller of my Nvidia GTX 1080 video card, and then finally they found rest in the graphics memory.
Sorry for this little caricature, but I had to emphasize somehow how awfully, terribly, mindboggingly slow the memory transfer is between the CPU and the GPU devices. In everyday use – which means games – you don’t recognise this, because game programmers are clever enough to prefetch all data ever needed for displaying graphics into the graphics card, so that they can minimise communication between the CPU and the GPU to the bare minimum.
Well, faults are paving the way to success, but the conclusions I have to draw from this are still a little bit sad:
- I will have to move all my data structures and calculations to the GPU.
- I will have to use CUDA C/C++ language, which does not allow me to create such nice code designs as I could do with proper C++14/17.
- The upside is that I will be able to run much more in parallel, not just matrix multiplications, so the expected performance gain is huge.
- I think that the difficulty of creating nice software designs on such high performance devices is limiting the number of software products that can make use of them.
Update: after creating a vector allocator class that uses cudaHostAlloc instead of the new operator I have managed to reach 1700 KCpS, yipeeee! The reason for this is that cudaHostAlloc pins down host memory so that the system will not be able to page it out, so when a memory transfer occurs cudaMemcpy has to do less checks, and the allocated memory block is already ready for the DMA controller without further preparations. Of course the real thing will be when I manage to implement an allocator that uses cudaDeviceAlloc, which will put everything immediately to device memory. However, it will also mean that all my calculations will have to be done on the device using CUDA kernel algorithms.
Final thoughts
Finally allow me to become a little bit nostalgic about some great hardware architectures of the past. Silicon Graphics used to be a leading manufacturer of high performance computers, all of which utilised a technology called UMA – Unified Memory Architecture. This meant that the main memory of the computer – the one accessed by the CPU – was also the graphics memory. When rendering 3D graphics you could instruct the CPU to do all sorts of things with the vertices or textures, all in parallel with the GPU.
Today only Intel provides such solutions with their sub-professional HD graphics chips, not even getting close to the performance and the novelties created by Nvidia. On the other hand, Nvidia only manufactures graphics devices that you can plug into your PC or laptop – so unified memory access is not anymore available for consumer – or even workstation – grade products. Unfortunately this remains a territory of very expensive supercomputers.
How awesome would it be to be able to write code in C++ 17, and telling the ‘unified compiler’ to execute some functions in parallel on the GPU – at zero cost? Well, until Nvidia buys Intel (or the other way around) I think we are not going to see such technology in our everyday computers. I think it is possible that ARM’s highly scalable RISC technology will reach our home PCs sooner than a collaboration from Intel and Nvidia. I think that the failure of the Knights Landing architecture that was originally intended to bring real-time raytraced graphics to mass products is also the first nail in the coffin of Intel – and the last going to be the SIMD instruction set. Anyhow, enough of whining, I have to work with what is available, so I am back to coding with CUDA.
Update: I have just found this video that backs up my claims that Intel is going to be taken over by ARM – apparently sooner than we would think: