Optimization Log
Sometimes performance gains come from weeks of rigorous profiling. Other times, they fall into your lap when you least expect them. In my recent work updating the DeepTrainer interface and cloud infrastructure, I stumbled upon significant speedups that pushed our benchmarks to new heights.
The 64-bit Surprise
Historically, I maintained the core project in 32-bit (x86), only compiling 64-bit for CUDA compatibility. I assumed that for the tight loops of matrix multiplication, 32-bit code was sufficient and lean.
However, deploying to an Azure Worker Role required an “AnyCPU” configuration, forcing a full 64-bit build of the native libraries. Out of curiosity, I ran the benchmarks.
Result: The 64-bit build was significantly faster. The increased number of available general-purpose registers (GPRs) in x64 mode likely allowed the compiler to unroll loops more aggressively and reduce register pressure, leading to fewer stack spills.
The Matrix Block Size Mystery: 4×4 vs 8×8
While rewriting the test harness, I added a UI toggle to switch the internal block matrix size between 4×4 and 8×8.
- Hypothesis: 8×8 blocks should be faster. They process more data per loop iteration and maximize the usage of SIMD bandwidth.
- Initial Observation: enabling 4×4 blocks resulted in a 5-10% performance boost.
This was baffling. Why would smaller blocks be faster?
The Padding Distortion
The culprit was the test topology: a simple 1-input, 1-output network with 256-neuron hidden layers.
- With 8×8 blocks, a layer input of size 1 is rounded up to 8 (7 padding zeros).
- With 4×4 blocks, a layer input of size 1 is rounded up to 4 (3 padding zeros).
The loop overhead was similar, but the 8×8 version was doing unnecessary math on padding zeros!
The Correction
To isolate the raw throughput, I changed the topology to 1x8x256x256x8x1. This ensures that the input/output layers align perfectly with an 8-wide boundary.
Corrected Result: 8×8 blocks regained their crown, beating 4×4 by ~1.5%. It was a small victory, but it restored my faith in the theory that wider interactions should be more efficient.
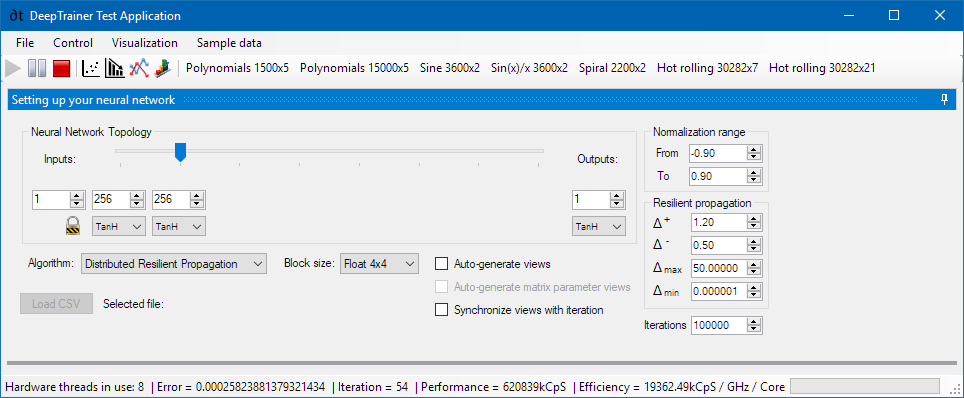
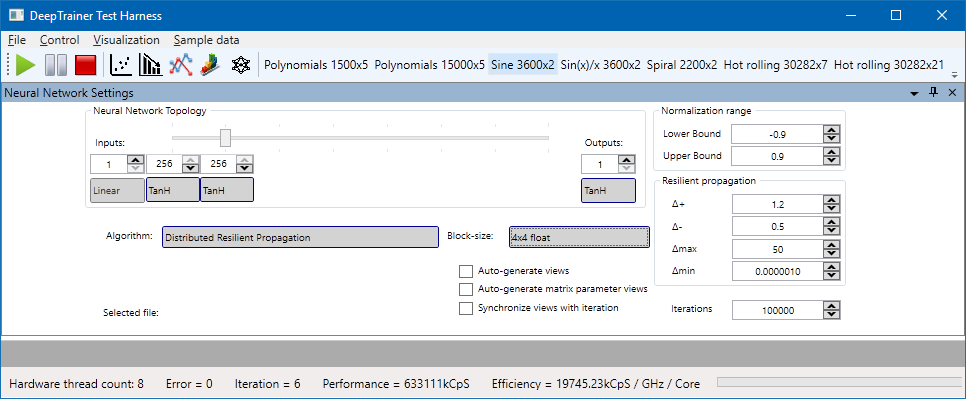
New World Records
With the combination of the 64-bit build and the topology-aligned testing, DeepTrainer has set a new personal record:
- Total Throughput: 633 MCps (Million Connections per Second) on a standard Core i7.
- Efficiency: 19,745 kCpS / GHz / Core.
This is nearly 20 MCps per GHz per Core, the highest efficiency density I have ever measured. Extrapolating this to the 40-core Xeon workstation I previously tested (which hit 0.93 GCps with the old code), I estimate we could now easily breach 1.5 GCps—potentially reaching as high as 1.86 GCps.
The fight for performance continues.